01PythonでGoogle画像検索での画像を一括ダウンロード

Google画像検索の画像一括ダウンロードの方法はPage3にあります.
web scrapingとは
ウェブスクレイピング(Web scraping)は、ウェブサイトからデータを自動的に収集するプロセスを指します.
具体的には、HTMLや他のウェブページの要素を解析して、テキスト、画像、リンク、表などの情報を抽出する作業です.
(ChatGPTさんより)
今回私はこのWebスクレイピングを学習し,Googleの画像検索画面の検索結果画像を自動的にダウンロードする ものを作りました.
チュートリアル
今回私はこのWebスクレイピングを学習するにあたって参照したサイトは以下になります.
上のサイトから以下のPythonコードをサンプルとして作成しました.
import requests
from bs4 import BeautifulSoup
import csv
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/107.0.0.0 Safari/537.36'
}
def scrape_page(soup,quotes):
#全てのdivタグ要素取得
quote_elements=soup.find_all('div',class_='quote')
#目的dataの抽出と保存の反復処理
#ここでquote_elementsではwebページのquoteクラスのリストができている
count=0
for quote_element in quote_elements:
#quote_elemtにquote_elementsというリストを一つ一つ代入して処理する
#textにquoteクラス内のさらにtextクラスのspanタグのテキストをリストとして代入
text=quote_element.find('span',class_='text').text
#同様にauthorクラスというsmallタグにも行う
author=quote_element.find('small',class_='author').text
#HTMLないquoteクラス内のaタグについても同様
tag_elements=quote_element.find('div',class_='tags').find_all('a',class_='tag')
# find_allを使った結果がlistとなっているため.textとして代入はできない
# .textは一つの要素に対して適用できる
#tagリストのテキストをlistとして保存
tags=[]
for tag_element in tag_elements:
tags.append(tag_element.text)
#quotesというlist内に辞書配列を入れている
quotes.append({'text':text,'author':author,'tags':','.join(tags)})
#','.join(tags)はtagsリストの要素を全てカンマ,で区切ってい一つの文字とするということ
time.sleep(1.5)
print('count',count)
count+=1
############################################################################
#対象webページのhome となるurl
base_url='https://quotes.toscrape.com'
#httpリクエストする際のheaderを設定しつつhtml読み込む
page=requests.get(base_url,headers=headers)
#dataの取得が成功したかどうか
if page.status_code==200:
print('http request successful')
#encodingの修正
page.encoding = page.apparent_encoding
#soupに解析(parse)したdataの格納
soup=BeautifulSoup(page.text,'html.parser')
quotes=[]
#上で作った関数でスクレイピングする
scrape_page(soup,quotes)
############################################################################
#次ページ遷移のhtml要素取得
next_li_element=soup.find('li',class_='next')
#次ページがあった場合の処理
while next_li_element is not None:
#href属性を持つaタグのみを取得
#['href'] を使い,a要素の href 属性にアクセスしその値を取得
next_page_relative_url=next_li_element.find('a',href=True)['href']
#次ページをrequestで取得
#homeページurlと次ページurlの相対パスを結合し,完全なパスとする
page=requests.get(base_url+next_page_relative_url,headers=headers)
soup=BeautifulSoup(page.text,'html.parser')
scrape_page(soup,quotes)
#次ページ内の次ページ要素
next_li_element=soup.find('li',class_='next')
############################################################################
#csvファイルの読込,作成
csv_file=open('quotes.csv','w',encoding='utf-8',newline='')
#newline='' はosによって異なる改行コード(\n)などを統一する
#上で作ったcsv_fileに書き込むためのオブジェクト作成
writer=csv.writer(csv_file)
writer.writerow(['Text','Author','Tags'])
pagecount=0
for quote in quotes:
writer.writerow(quote.values())
print(pagecount)
pagecount+=1
csv_file.close()
このようにスクリプトを作成しました.ここからweb scrapingの基本構造を学びました.
ここから自分でスクリプトを再度作成し求めるものとしました.
ついぎに作成したスクリプトを載せます.
02Google画像検索の画像一括ダウンロードのコード
コードを自分で書く
Webs crapingの学習が一通り終わったので自分でコードを書きました.
そこで私が作ったのが「Google画像検索の一覧画像を一括ダウンロードする」コードです.
以下のサイトを参照しました.
[毎日Python]Pythonで新しいディレクトリを作成や上書きする方法
Pythonでファイルが存在するかどうかを確認する方法
Requestsで日本語を扱うときの文字化けを直す
これらのサイトを用いつつ下のコードを作りました.
import requests
from bs4 import BeautifulSoup
import os
import shutil
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/107.0.0.0 Safari/537.36'
}
############################################################################
url=input('Enter google img URL')
page=requests.get(url,headers=headers)
if page.status_code==200:
print('http request successful')
page.encoding=page.apparent_encoding
soup=BeautifulSoup(page.text,'html.parser')
def scrape(soup):
soup_divelems=soup.find_all('div',class_='bRMDJf')
imges=[]
for divelem in soup_divelems:
data=divelem.find('img')
imges.append(data)
print('extracting img tags successful')
urls=[]
for imgsrc in imges:
src=imgsrc.get('src')
data_src=imgsrc.get('data-src')
urls.append(src)
urls.append(data_src)
print('extracting url successful')
#None消去
urls=filter(None,urls)
urlsf=list(urls)
print('removing None finished')
#画像保存
#ディレクトリ作成と同ディレクトリ名の回避
i=0
a=0
while i==0:
check=os.path.exists(f'./scrapedimages{a}')
if check:
print(f'file name scapedimages{a} exists')
a+=1
continue
os.makedirs(f'./scrapedimages{a}',exist_ok=True)
dir_name=f'scrapedimages{a}'
print('deciding file name finished')
a=0
i=1
for i in range(len(urlsf)):
# dataURI識別
first_string=urlsf[i][0]
if first_string=='d':
continue
response=requests.get(urlsf[i])
image=response.content
file_name=f"scraped_image{i}.png"
with open(os.path.join(f"./{dir_name}",file_name),"wb")as f:
f.write(image)
print(file_name,'downloaded')
shutil.make_archive(dir_name,format='zip',root_dir=dir_name)
print('scrape finish')
i=0
scrape(soup)
このスクリプトでは
まずGoogleの画像検索のURLから各画像のURLを抽出しています.
次にそのURLから画像を保存し,フォルダを作成します.
最後にそのフォルダをzipに圧縮し保存を可能にしました.
製作時間は半日ほどです.
このコードの欠点は画像のURLがDataURIでは取得できないという点です.
DataURIでは一度画像に変換した後にダウンロードする必要があります.
その変換には他のWebサイトを経由する必要があり,今回はhttpsプロトコルの画像のみをダウンロードすることにしました.
要は,このコードでは全ての画像がダウンロードできるわけではないという事です.
コードの以下の部分でDataURIとHTTPを区別しています.
# dataURI識別
first_string=urlsf[i][0]
if first_string=='d':
continue
次にこのコードをどのように使うのか解説します.
03コードの使い方
Google Colaboratoryを使ってコードを実行
このサービスを利用する場合は本社の利用規約に同意したものとします.
利用規約
コードを実行するにはGoogle Colaboratoryを使います.
下のURLに飛んでください.
https://colab.research.google.com/drive/1dtiE0dP3bigEErF6QZ9jPwN-JK2_HZif?usp=sharing
上のURLをクリックすると次の画面になります.
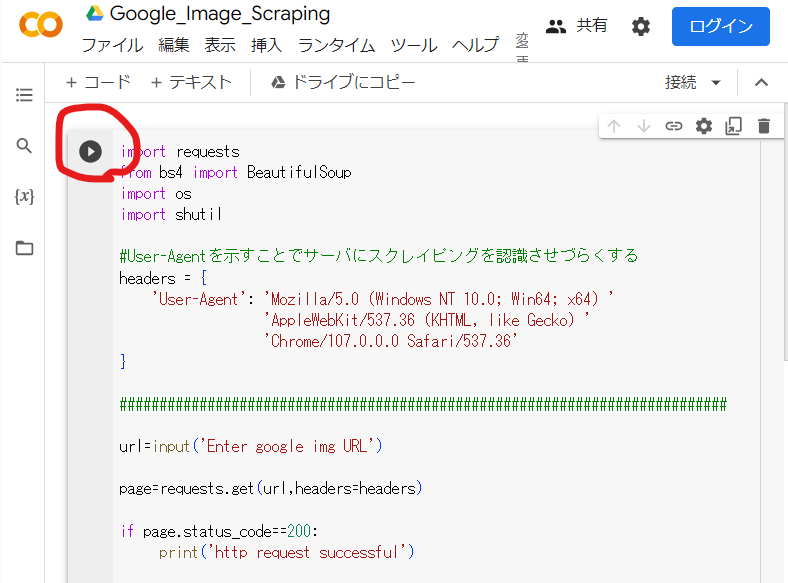
この画面の赤丸で囲んである矢印を押してください.
このボタンを押すことによってプログラムコード自体が実行されます.
押すとログインしていない場合は以下のポップアップが表示されます.
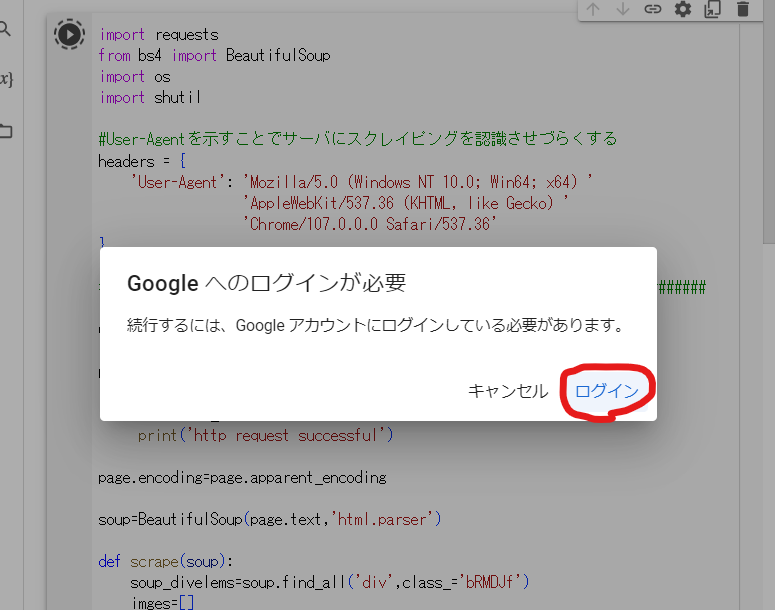
上の赤丸からログインしてください.
特に登録していなくても,ご自身のGmailのメールアドレスでログインできます.
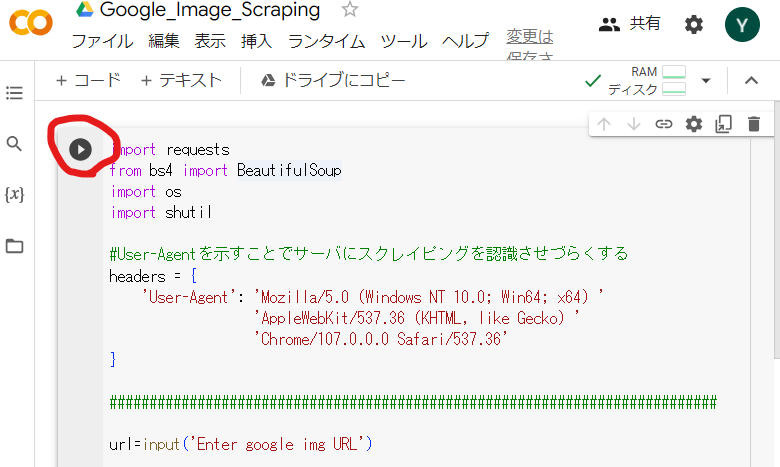
ログイン後,再度赤丸の矢印ボタンを押してください.
すると以下のような警告ポップアップが表示されます.
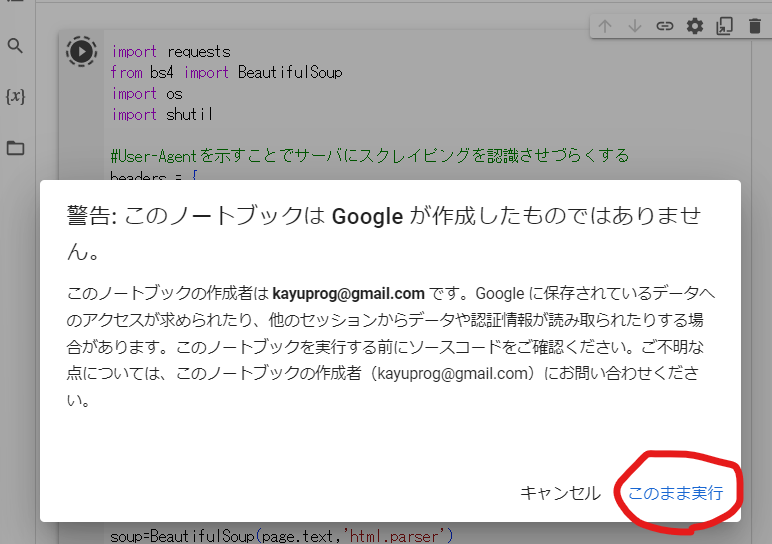
赤丸の「このまま実行」を押してください.
すると,しばらくしたのちにページの下の部分に次の写真のようなURLを入力する欄が出てきます.
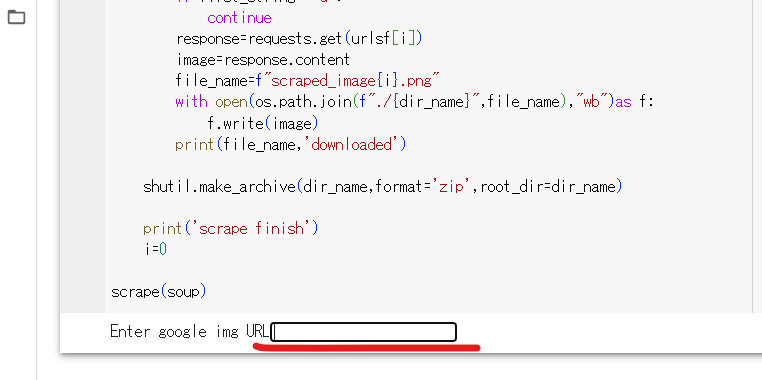
ここにGoogleの画像検索のURLを入力してください.
Googleの画像検索のURLは以下の写真の赤線部分を指しています.
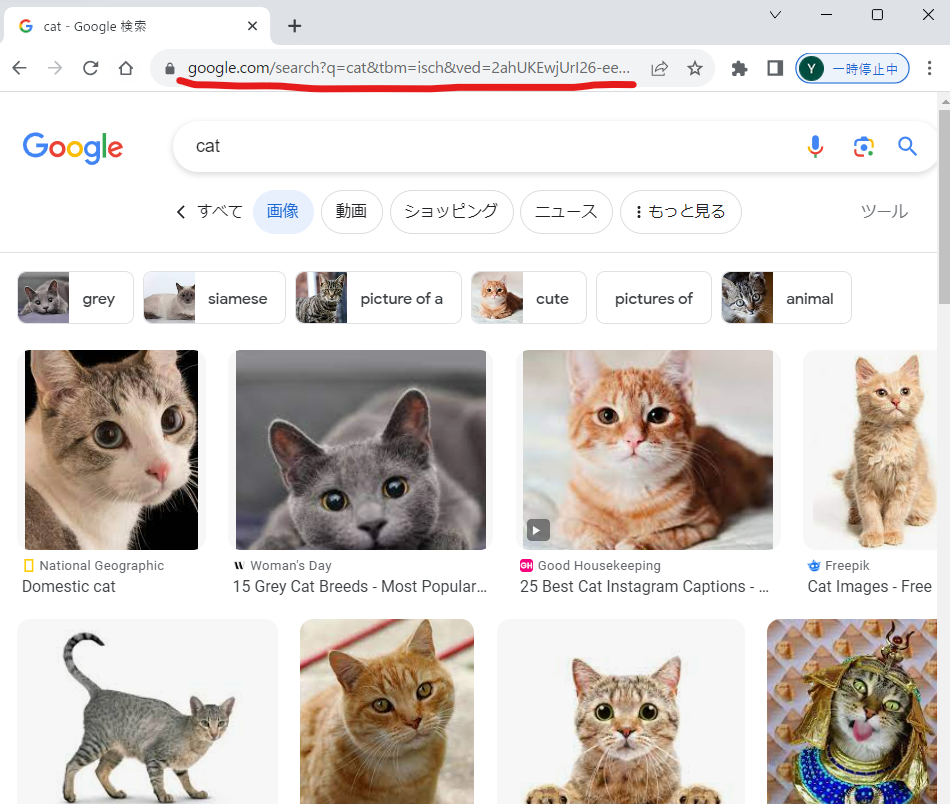
このURLをコピーしてください.
注意点として,URLを https://~ から全てコピーしてください.
そのURLを先ほどのURLを入力する欄にペーストします.
次にEnterキーを押すことによってスクレイピング(Webの解析)が開始します.
しばらくすると左(PCによる)のフォルダタブにzipファイルが現れます.
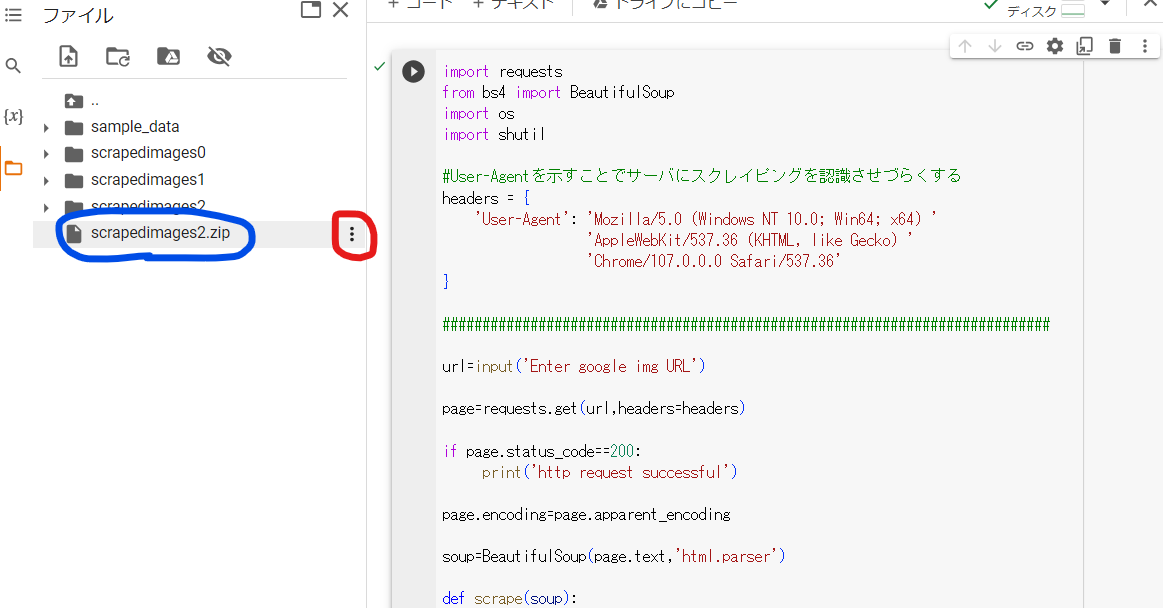
図の青丸が作成されたzipファイルにあたります.
ファイル名はこの図とは異なると思います.
*具体的には番号が違います.
図の赤丸を押すとzipファイルをダウンロードできます.
フォルダ内にはGoogle画像検索の結果として表示されたものが保存されています.
ご活用ください.
今回の記事は以上です.ありがとうございました.